How to build a custom Harvesting Module with Java#
This tutorial will show you how to write a simple Harvesting module in Java by example based on the piveau pipe and the corresponding Connector library. The module will be placed between the importing and exporting module and be able to manipulate the harvested data. This is helpful if you want to enrich, transform or correct your data for a specific use case. You find the code for this tutorial here.
Prerequisites#
- Basic knowledge of piveau
- Reading the Harvesting introduction
- A running instance of piveau hub-repo and hub-search (see Quick Start)
- Docker, Docker Compose, JDK >= 17, Maven 3, IDE
Overview#
As an example we want to harvest the metadata of the European Fisheries Control Agency into our piveau instance. To enrich the data, we want to add the keyword "fish" to every dataset to increase findability of the data. We find the data in a dedicated catalogue in data.europa.eu. The data can easily be harvested from the piveau API of data.europa.eu:
https://data.europa.eu/api/hub/repo/catalogues/cfca/datasets?valueType=metadata
We will use three basic consus modules to set up the harvesting pipe: piveau-consus-importing-rdf, piveau-consus-exporting-hub and piveau-consus-scheduling. The entire pipeline will then look like this:
flowchart TD
data(data.europa.eu API) --> consus-importing-rdf
consus-scheduling -. triggers .-> consus-importing-rdf
consus-importing-rdf --> module{{pipe-module-example}}
module--> consus-exporting-hub
consus-exporting-hub --> hub(hub-repo)The API of data.europa.eu will return the datasets as RDF and the importer will forward it dataset by dataset to our custom module. Our module will add the keyword and forward each dataset to the exporter, that exports it to our hub instance.
Let's get started#
Info
The following steps assume that you have a running version of hub-repo on http://localhost:8080 and a catalogue created with the ID cfca (check http://localhost:8080/catalogues/cfca)
The starting point is our module example repo. Just clone it:
$ git clone https://gitlab.com/piveau/pipe/piveau-pipe-module-example.git
$ cd piveau-pipe-module-example
- In the pom.xml we include the
pipe-connectorlibrary, which does all the heavy lifting for you, so you can concentrate in writing your actual logic. - Also you find there
piveau-utils, a library including some helper functions especially for RDF handling. - The
MainVerticle.javais the actual application and just a simple Vert.x Verticle. - The
docker-compose.ymldefines and starts all the services for this tutorial and can act as a blueprint for your custom pipeline. - The
pipesdirectory includes the example pipe descriptor to harvest the data from data.europa.eu, send it it to our custom module and finally to the exporter. - The
Dockerfileto build and deploy your module.
The Module#
Let us have a look into the actual code. There is not so much you need to do. The PipeConnector object will magically transform the Verticle into a pipe module. It creates a HTTP server (by default in port 8080), that complies with the pipe concept and encapsulates all the data processing and orchestration tasks. You find more details in the code:
public void start(Promise<Void> startPromise) throws Exception {
Future<PipeConnector> pipeConnector = PipeConnector.create(vertx); // (1)!
pipeConnector.onSuccess(connector -> {
connector.handlePipe(pipeContext -> { // (2)!
Model model = Piveau.toModel(
pipeContext.getStringData().getBytes(),
Lang.NTRIPLES
); //(3)!
Resource dataset = Piveau.findDatasetAsResource(model); //(4)!
if (dataset != null) {
dataset.addProperty(DCAT.keyword, "fish"); //(5)!
}
pipeContext.setResult( //(6)!
Piveau.presentAs(model, Lang.NTRIPLES), //(7)!
Lang.NTRIPLES.getHeaderString(), //(8)!
pipeContext.getDataInfo()) //(9)!
.forward(); //(10)!
});
});
startPromise.complete();
}
- The basis is a PipeConnector object that gets the current Vert.x instance.
- This handler is automatically called for every dataset and gives you the current PipeContext.
- We use a handy helper function from the piveau utils library to transform the data stored in the PipeContext into a Apache Jena model. The importer is returning N-Triples, so we need to use the same here.
- We extract the actual Dataset from the model. (A model can include multiple graphs).
- The actual additional keyword is added here.
- The enriched dataset (as part of the model) is set in the PipeContext as result.
- The model gets serialized as N-Triples
- We need to set the mime type of the data
- The importer sets the target catalogue ID in the data info part, so we need to include it.
- We forward the payload to the next pipe module
Running it#
Now, we want to test our pipe module. We are using Docker Compose to run all the modules. For easier network integration of our new module, we will also build, provide and run it as a Docker container. If required you can also build and run it directly with Maven. However, please refer to the official Docker documentation how to setup a suitable network.
Build the module with this command:
Then you simply start all the services:
You can now investigate the pipe endpoint, that is generated by the PipeConnector library. Just browse to http://localhost:9083/
Now we trigger the scheduler to start the harvesting:
$ curl -i -X PUT -H 'Content-Type: application/json' --data '{"status": "enabled", "id": "immediateTrigger"}' 'localhost:9080/pipes/cfca/triggers/immediateTrigger'
If you want you can monitor it via the logs:
Finally, you should find the harvested datasets tagged with "fish" in hub-repo: http://localhost:8080/catalogues/cfca/datasets?valueType=metadata
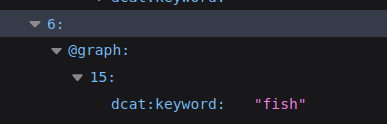
That's it! You have created a very simple pipe module
Tipps#
If you want to develop on the module you can use the following two commands to rebuild it and restart it:
$ docker build -t piveau-pipe-module-example .
$ docker compose up piveau-pipe-module-example --force-recreate -d
Further Reading#
If you want to dive deeper into the topic you can have a look into the code of the many existing pipe modules: https://gitlab.com/piveau/consus